
快訊
- 颱風來到家門口!巴威陸警「擴大至12縣市」南投、台中入列
- 藍核能公投提案再延後 3公投案「先來先走」?國民黨團:黨團大會討論
- 熱浪續炙烤歐洲 德國逾5千人熱死、西班牙創112年高溫紀錄
- 視導中央災害應變中心 賴清德3點指示:地方政府有任何需求就通知中央
- 大雨特報!涵蓋北北基桃8縣市 巴威颱風外圍環流發威了
- 全台12縣市放颱風假 台東縣蘭嶼、綠島鄉13:00起停班停課
- 致癌沙拉油風暴!中聯總經理聲押 董座2千萬交保
- 暗殺風險大?川普棄搭新空軍一號 改搭舊機離開土耳其
- 18:00起停班課遭「斷絕母子關係」!盧秀燕喊話「市民家人」淹水示警
- 預測機構:聖嬰效應加持 今年颱風季活躍度將大增4成
- 「母載女兒遺體」拒報案、想跑 離奇車禍...揭伴屍原因超鼻酸
- 「價格上不能輸」 日Rapidus社長:半導體售價會比台積電更低
- 伊朗邊下葬哈米尼邊報復攻擊美軍 美官員:技術性協商持續
- 轎車自撞驚見「載1具女屍」 詭!駕駛媽堅稱:女兒沒死
- WSJ:以色列通報美國 伊朗正醞釀暗殺川普
- 巴威移動速度放慢!氣象粉專:暴風圈觸地延至深夜,明雨勢恐非常可觀
- 網紅「蹦闆」70萬交保!發聲:希望各位相信我 涉章魚燒討債案內幕曝光
- 台積電代工 路透:Meta自研AI晶片今年9月起生產
- SK海力士在美掛牌募得265億美元 超越阿里巴巴登美股史上第二大發行案
- 世足賽》遭暴力剷球衝擊腳踝換下場 姆巴佩:我很好沒事
【AI感受調查6-3】打造台灣主權AI:語言文化與資料隱私的雙重挑戰
2025-05-26 08:10 / 作者 洪敏隆

世界許多國家都在發展本土式語言模組,建構主權AI。本報繪製
生成式AI在全球帶起風潮,要鞏固主權AI,台灣必須推動大語言模型,發展符合國家價值觀的AI模型。不過,根據《太報》委託皮爾森數據公司進行的「生成式AI學習適應與衝擊感受調查」顯示,有四分之一的受訪者完全不願意提供任何個人資料,願意提供類型也集中在相對較少涉及隱私的資料。
全世界有近7000種語言和文字,但在美中競爭大環境下,目前國際生成式AI模型,訓練資料多以英文為主,中文則以簡體中文為大宗,如果非在該語系國家的語境下使用,很容易產生不符合使用者生活、文化背景需求的解釋及用語。
根據本次調查,有使用生成式AI經驗的民眾中,有43.5%認同曾因出現簡體中文/中國常用語感到困擾,完全不會困擾或從未發現/從未遇到這種狀況的受否者合計不到2成(18%)。
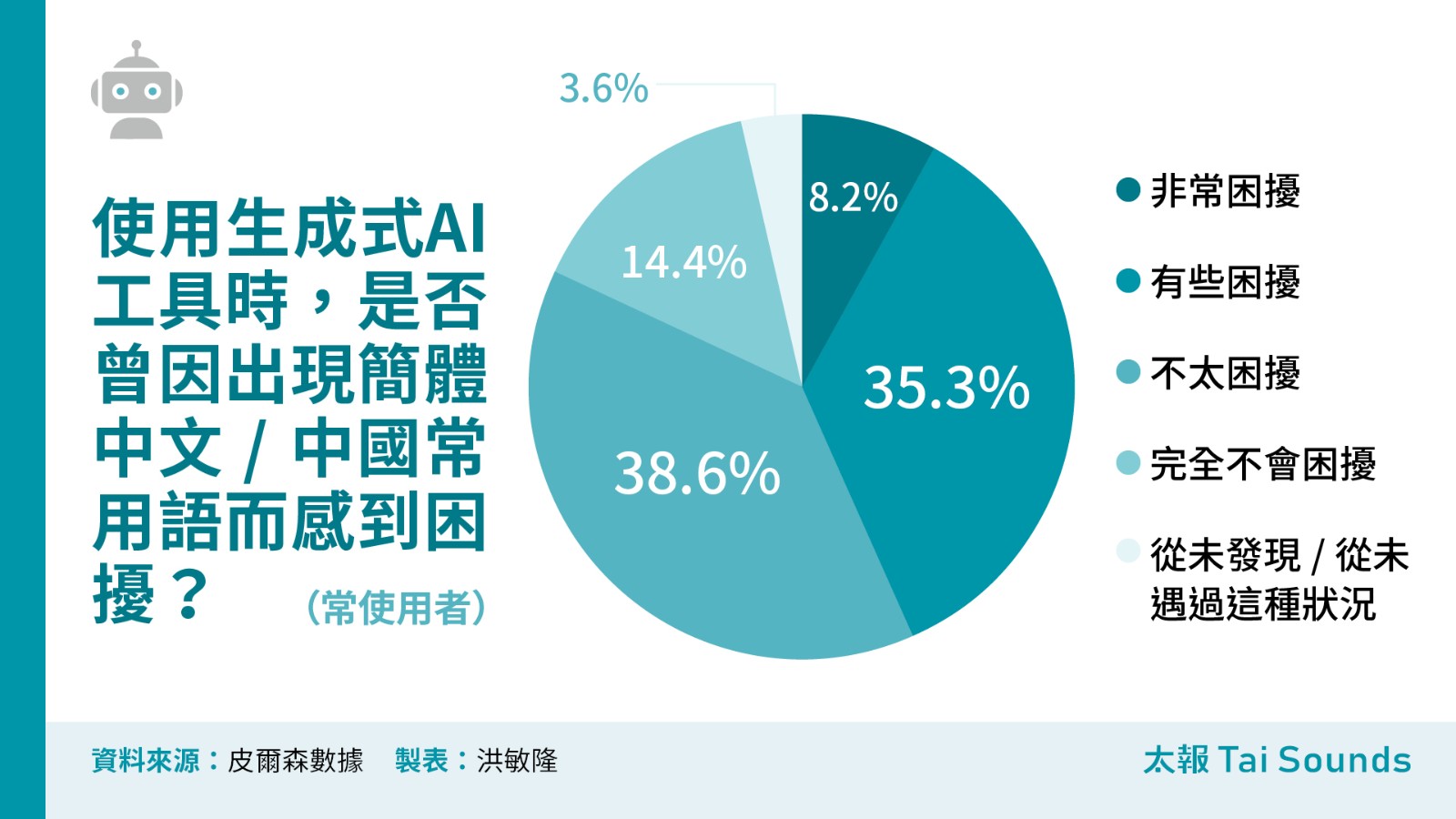
其中,女性認為困擾比例更高,有接近5成比例(49.6%),反觀男性有超過6成認為即使遇到也不會太困擾(60.1%)。值得關注的是,18-29歲的年輕族群與60歲以上的高齡族群,相較其他年齡層更感到困擾,分別有58.4%及51.4%。
當問到選擇「很少/幾乎沒有使用」生成式AI的受訪者,與頻繁使用生成式AI的族群相比,在使用時若遇到簡體中文或中國用語,預期自己會有更高的困擾感受,整體比例達到61.3%,其中以高齡族群(60歲以上)與女性族群的困擾感特別明顯,分別有62%及66.3%。
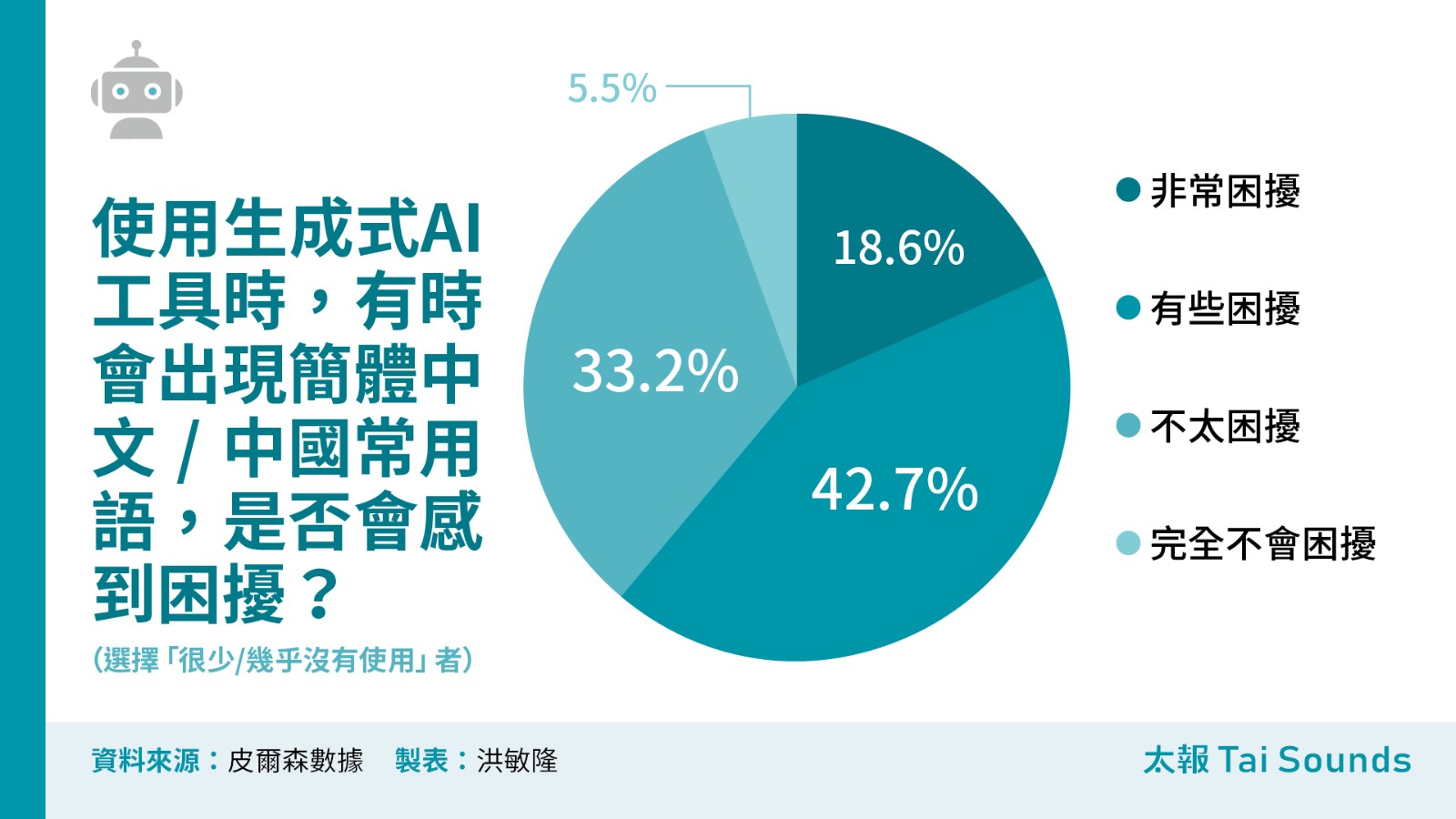
在出版社工作的阿傑說,最困擾的不是AI回答問題時會跳成簡體字,這可以再次下指令「用正體字回答」,可是簡體字改了,但是用語還是中國式的,甚至回答的都是中國而非台灣的生活情況或法律規定。
陽明交通大學科技法律學院特聘教授林志潔說,雖然現在的AI服務有提供繁體中文,但可看出句中的詞彙用語與台灣平時使用的習慣並不一樣,背後多為中國簡體中文直接轉述,因此,目前正在研議制定的「人工智慧基本法」草案應該納入主權的概念,不只攸關科技發展,更攸關國家安全。
國民黨立委葛如鈞在立法院「人工智慧基本法」草案公聽會也強調,目前台灣在建構符合本地語言文化、教育人才、創新發展、社會信任的「繁體中文語料庫與主權大型語言模型(LLM)」方面,資源匱乏,資料更是稀缺,政策推動力道不足,若再不積極行動,台灣特有的繁體中文文化、價值觀,很可能在全面 AI化的未來,被簡體中文取代、使得繁中消失於全球、甚至全宇宙。
「每個國家都要有自己生產智慧的能力。」Nvidia執行長黃仁勳去年(2024)2月在杜拜舉行全球政府高峰會上曾喊話,各國政府應該積極投入發展「主權AI」(Sovereign AI),強調每個國家需要擁有自己的AI基礎設施,在享受AI發揮經濟潛力的同時,保護自己的文化,「你絕不會允許讓其他人來做」。

輝達執行長黃仁勳曾呼籲,各國都應積極發展主權AI。路透社
Nvidia將主權AI定義為一個國家利用自己的基礎建設、資料、人才和商業網路來發展人工智慧的能力,特別是運用自己的語言、文化資料來發展各國自己的大語言模型。
目前許多國家都已投入發展主權AI,其中,新加坡政府建置SEA-LION大型語言模型,包含華語、英語、緬甸語、菲律賓語、高棉語、寮語、馬來語等11種東南亞地區使用的語言資料。日本、韓國也宣布投入經費,政府與民間合作建置大型算力資源。

國科會推動的TAIDE。畫面截自國科會網站
台灣目前發展類似主權AI的模型是國科會推動的TAIDE(Trustworthy AI Dialog Engine,可信任的AI對話引擎),以台灣文化為基礎,融入台灣語言、價值觀、習俗等元素打造,能夠理解和回應台灣用戶的需求。
在行政院智慧國家推動小組民間諮詢委員會上,台灣大學資訊工程學系副教授陳縕儂指出,台灣開發生成式 AI 需要大量的資源(包含開放資料授權、有彈性的專責負責單位),如何凝聚共識讓有資料的人願意釋放資料、有技術能力的人願意共同貢獻技術能量,會是非常重要的挑戰,也是台灣是否能夠發展出成功案例的重要要素。
陳縕儂提到,具資料所有權者相對保守,政府應鼓勵資料開放,保障開發者的使用資料權,才能使技術人才更有意願投入(由下而上),例如:所有學校教科書、教材試卷等,或可直接開放給模型訓練。
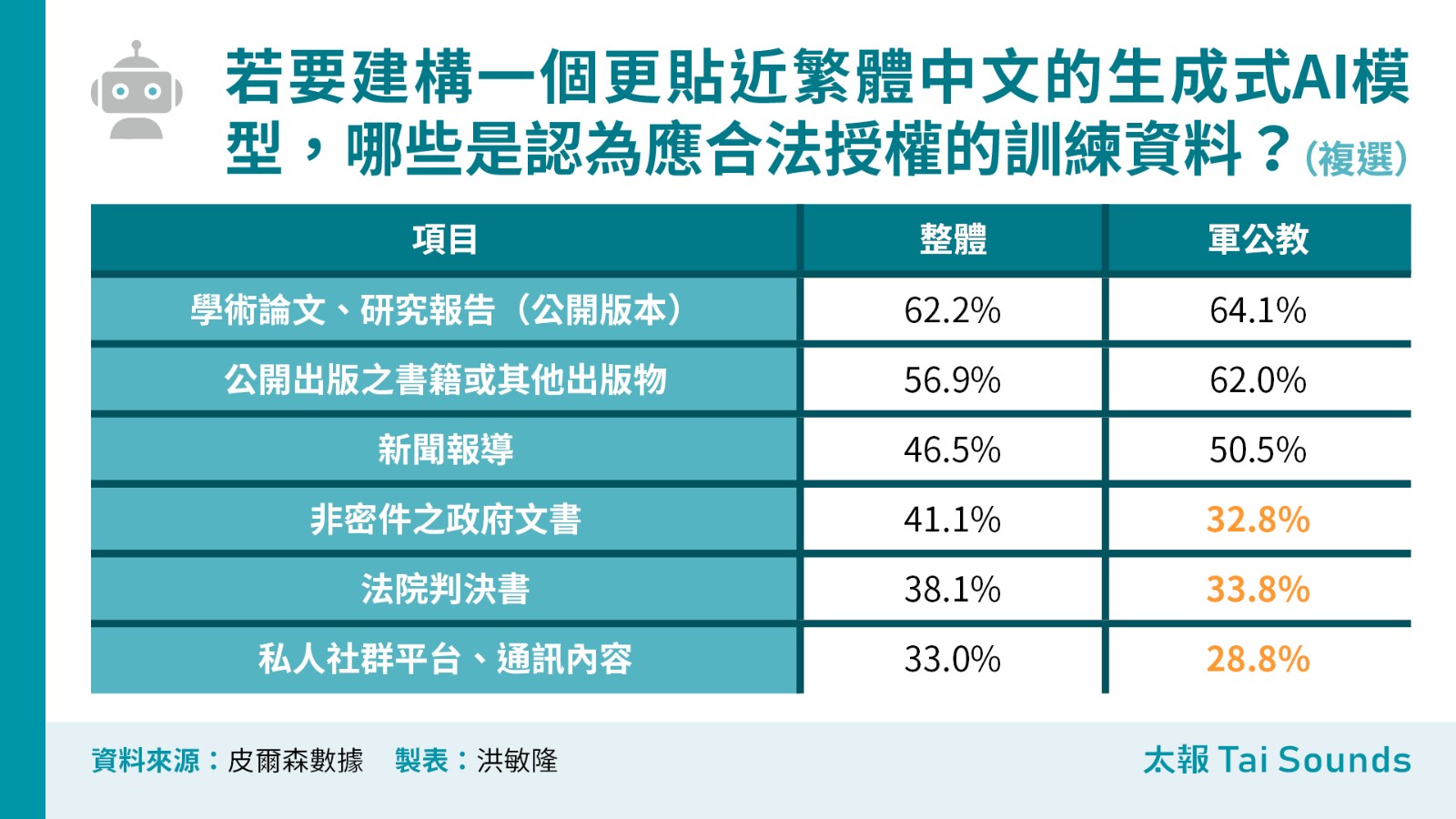
《太報》本次調查,台灣民眾對生成式 AI 模型應合法授權哪些資料進行訓練,仍傾向以正式出版或公共領域資料為主。受訪者當中,有62.2%選擇「學術論文、研究報告(公開版本)」,其次是「公開出版之書籍或其他出版物」(56.9%),這兩項皆有過半數的選擇比例,排名第三是「新聞報導」(46.5%)。
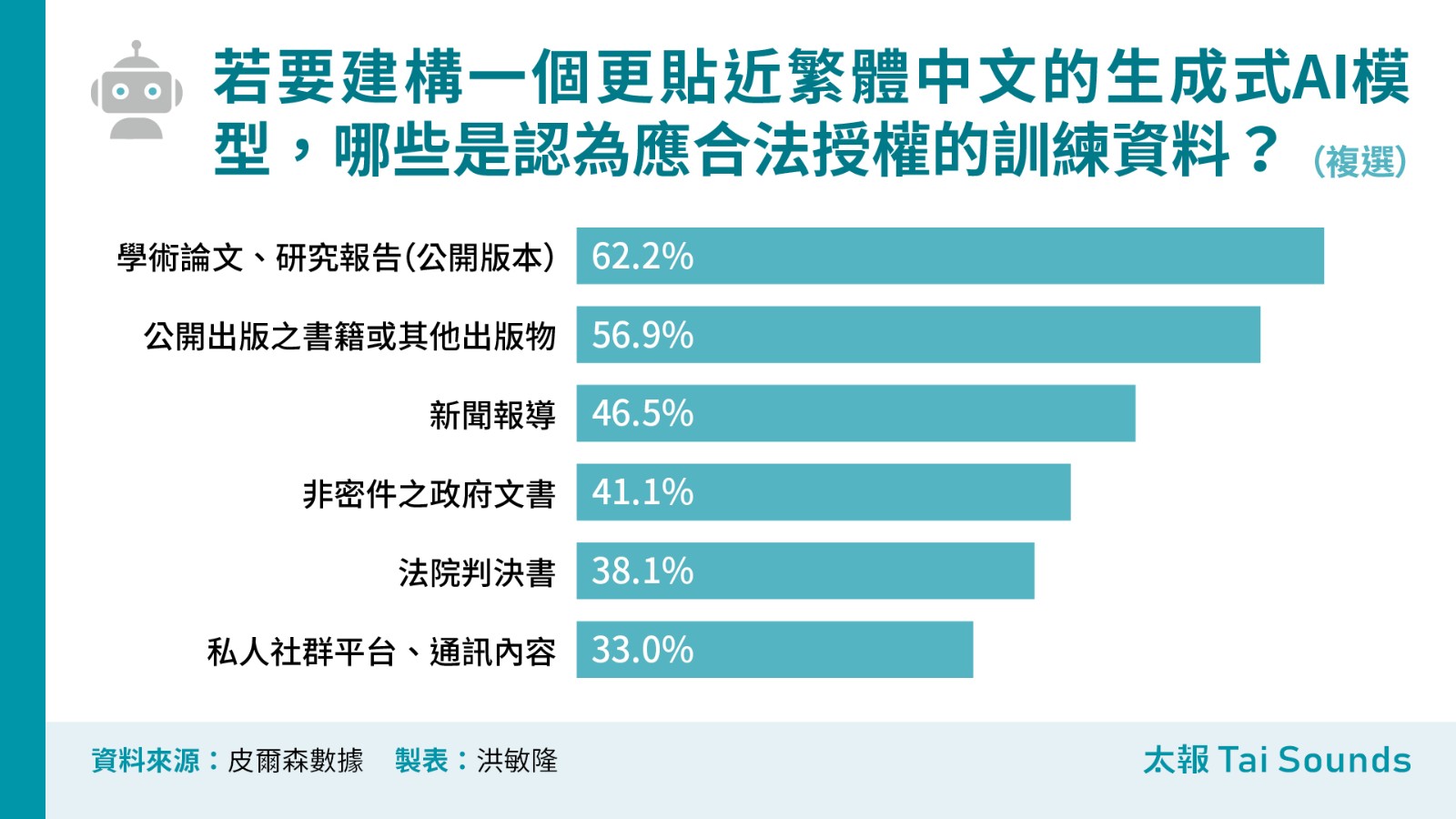
至於「私人社群平台、通訊內容」的授權支持度最低,僅有33.0%。值得注意的是,雖然男性在各類資料類型上,普遍認為應合法授權的比例高於女性,但在私人社群平台與通訊內容的部分則表現出較高的保留態度,贊成者只有31.5%,低於女性的34.3%。
另從年齡層觀察,私人社群平台內容作為合法授權資料的接受度隨著年齡增加而上升,從18-29歲族群的23.4%,上升至60歲以上族群的41.8%,反映出不同世代對個人資料隱私界線的認知與接受度存在顯著差異。
另一個值得觀察的是軍公教的意向,在「學術論文、研究報告(公開版本)」、「公開出版之書籍或其他出版物」、「新聞報導」的認同度都遠高於整體,但是在「非密件之政府文書」及「法院判決書」的認同度卻遠低於整體,未來政府在相關AI主權推動的工作,政府機關本來是否願意「帶頭起示範作用」,也會是未來可觀察的方向。
本次調查也針對民眾願意提供什麼樣的「個人資料」,以建構台灣本土的生成式 AI 模型,結果發現民眾對此較為謹慎,有25.3%的受訪者表示完全不願意提供任何個人資料,女性不願提供的比例(28.5%)比男性高(21.6%)。
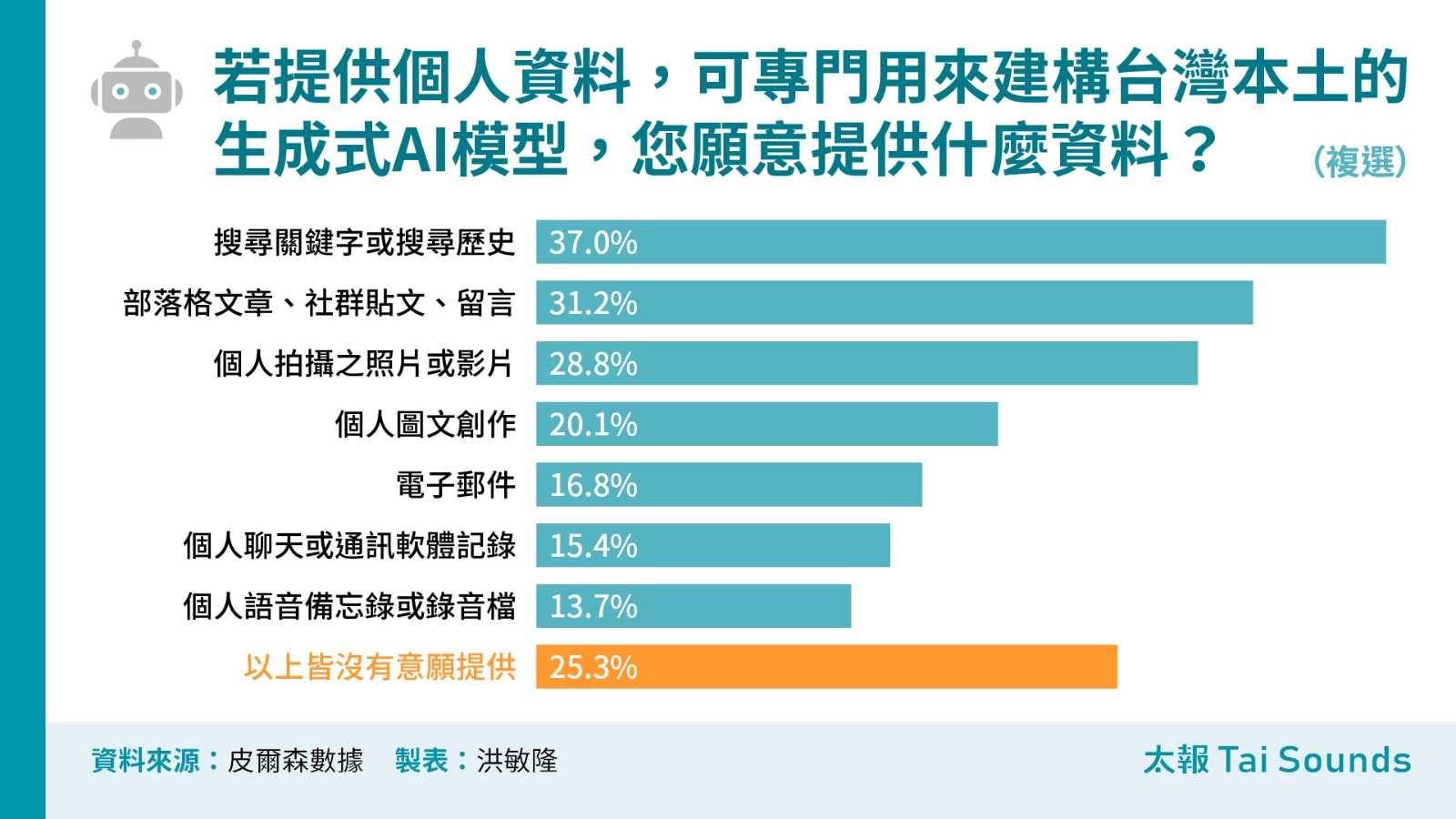
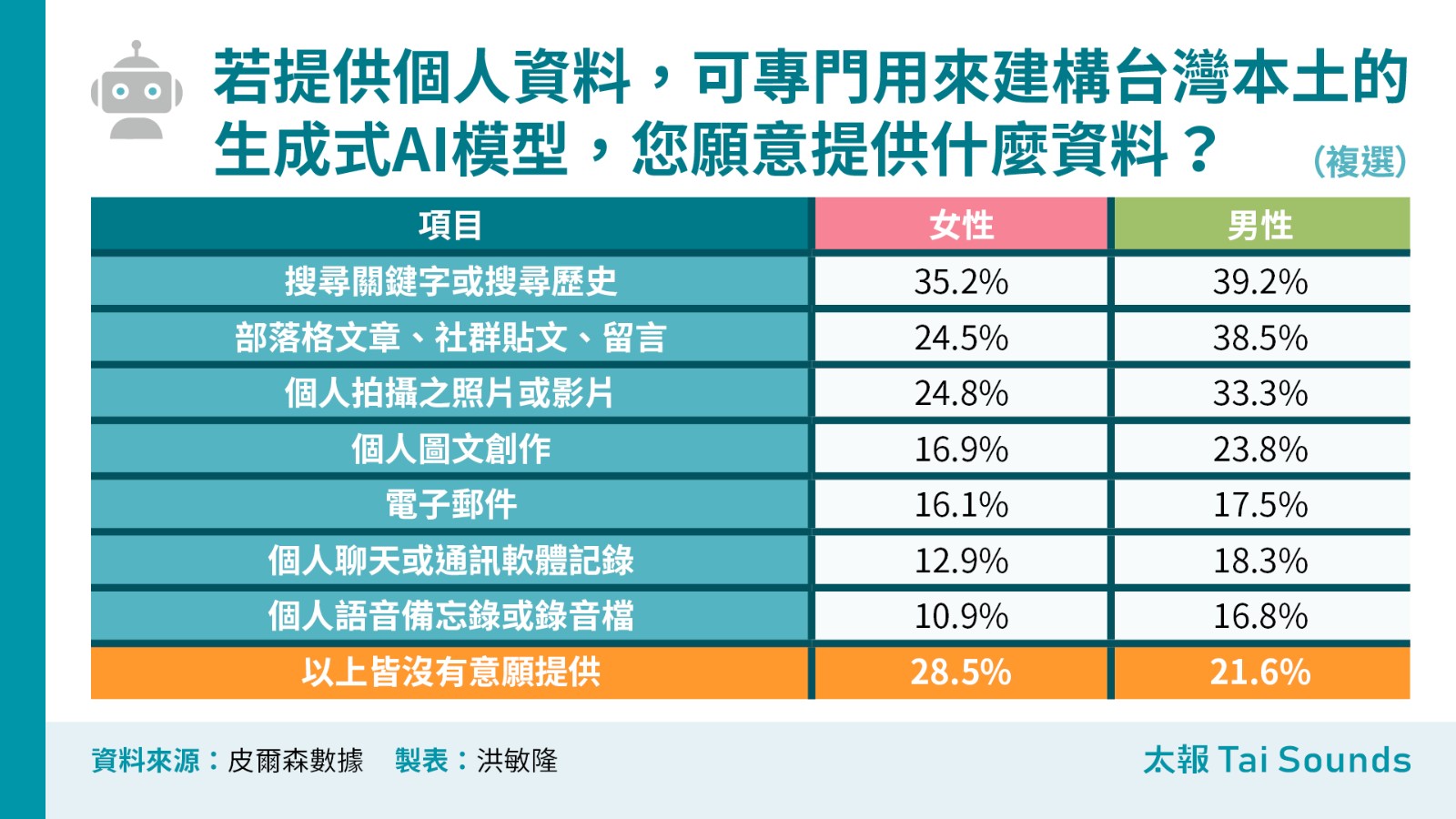
在願意提供的類型中,主要集中於相對較少涉及隱私的資料,如搜尋關鍵字或搜尋歷史(37.0%)、部落格文章、社群貼文、留言(31.2%)、以及個人拍攝之照片或影片(28.8%)等。至於涉及更私密的文字或語音資料,如電子郵件、聊天記錄、語音備忘錄,提供意願皆低於兩成。
男性提供個人資料的意願普遍高於女性,尤其在「部落格文章、社群貼文、留言」(38.5%)與「個人拍攝之照片或影片」(33.3%)兩項,男性的提供意願明顯高於女性的24.5%及24.8%。年齡層分析,高齡族群(60歲以上)整體提供意願相對較低,特別是在涉及個人隱私的資料類型上表現出更為保守的態度。
從調查可看出,政府未來若要推動主權AI,如何確保AI技術的應用符合社會公義、尊重人權,並能有效管控潛在風險,讓AI技術與社會發展的良性互動,是未來成功不可或缺的基礎。

最新more>
- 金塊誤丟垃圾車!台南清潔隊10分鐘找回 「黃金救援」關鍵曝光
- 巴威颱風逼近!票據交換所:存款不足退票 將從寬處理祭2措施
- IU、李鍾碩熱戀4年分手了!經紀公司證實:以前後輩關係相處
- 巴威颱風來襲!央行外匯局堅守崗位 提供資金5.85億美元外幣資金
- 颱風來到家門口!巴威陸警「擴大至12縣市」南投、台中入列
- 颱風假一宣布北車高鐵站塞爆!網哀嚎「對號座都差點擠不上」:窒息感滿滿
- 高雄外包工清吊扇慘摔2公尺亡!雇主夫妻未做好這件事遭判刑
- 藍核能公投提案再延後 3公投案「先來先走」?國民黨團:黨團大會討論
- 颱風天南港LaLaport、美麗華照開 蔣萬安籲:安全優先
- 【每日揭詐】以為貨到付款最安全!臉書代購智慧手錶驚收「山寨粗糙品」
熱門more>
- 台中建築師墜樓震撼業界 逾600同業痛心連署:有限報酬卻扛無限責任
- 妻拜「九尾狐」招桃花!台中畸戀3人同居「夫被鐵鎚打死」 家屬獲賠390萬
- 「心臟不適」直播主大鬧急診室 三字經飆罵醫護嗆「來告」還po網公審
- 張凌赫自爆「4疾病」纏身 曾跌至66公斤「要人攙扶」粉絲嚇壞
- 驚嚇破表!彰化13歲男童遭10多隻流浪犬追咬
- 快訊/大立光林恩平:7、8月動能逐月增! 收到CPO客戶規格7月將送樣
- 魔嫂司曉迪「睡完頂流加床照」案外案!鹿晗、關曉彤掰了8年戀 最後一次互動網狂扒
- 李洋出手!整頓寄生亂象 11個協會年底前恐須搬離體育大樓
- 明年手機鏡頭新亮點曝光!大立光林恩平:潛望鏡、新規格主鏡頭升級來了
- 台中街頭情殺「補刀插頸、坐看她斷氣」 恐怖前任「定位追蹤」謀殺計畫曝!5罪起訴